Nosokinetics
Mining length of stay data for better understanding patient flow
Revlin Abbi, PhD Candidate, Harrow School of Computer Science, University of Westminster
(comments to abbiR@westminster.ac.uk)Data mining is the process of extracting knowledge from large volumes of historical data. The objective is to discover patterns in the data that help explain current behaviour or predict future outcomes.
Classification, a branch of data mining, is an approach often used to enhance understanding (by extracting information) and to make predictions about the future. By classification we mean the act of distributing objects into groups of similar type.
In our case, we wish to distribute records representing patient spells, into non-overlapping, mutually exclusive length of stay (LOS) classes, where each class represents a LOS interval range. To achieve this aim we are working on developing a patient spell classification methodology. The methodology classifies patient spells according to the patient LOS variable.
Based on the classification, a model is derived that can be used for both descriptive and predictive purposes. The model is descriptive as it extracts specific and unique characteristics (profiles) for each LOS class. It is also predictive as we hope to make it is generic enough to correctly predict the LOS of unseen or future patient admissions.
To discover classes, from the LOS data, the methodology incorporates a two-stage process. Stage one fits a Gaussian mixture model (GMM) to discover LOS groups, Figure 1. These groups are probabilistically defined and thus tend to overlap with one another.
Stage two derives LOS classes from the LOS groups (using the Bayes theorem). The GMM is a probability density model consisting of a mixture of normally distributed component functions. We have shown that, given the right number of component functions, the GMM is capable of approximating the skewed LOS distribution.
For example, a five-component GMM can be fitted to a data set of stroke patients, Figure 1. From the estimated GMM parameters, we are able to derive the mean, variance and the percentage of patients belonging to a LOS group.
The mean can be used as an indicator of the expected stay of admitted patients and the variance to describe the homogeneity (variation) within each group. The percentages can be used to determine how many of the admitted patients are likely to have short, medium or longer stays. Based on the GMM in Figure 1, the five classes are defined as 01-02 days, 03-12 days, 13-29 days, 30-70 days, and 71+ days.
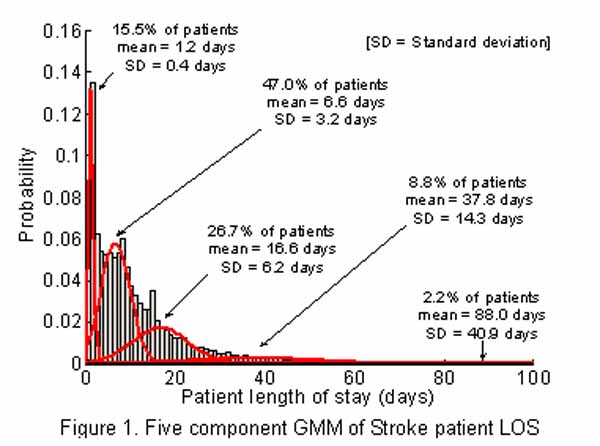
Figure 1: a Gaussian mixture model (GMM) to discover LOS groups.
To estimate future prediction performance the decision tree is applied to a set of unseen patient records. In this case, the performance measures are used to indicate how well the tree is likely to perform. The tree can then be used, with confidence, to classify future patient admissions into the most likely LOS class.
In summary, the proposed methodology provides an innovative approach to classifying patient spells according to their LOS. The approach provides a simplified representation of the patient population, which may help to improve the planning and management of patient care.
Some navigational notes:
A highlighted number may bring up a footnote or a reference. A highlighted word hotlinks to another document (chapter, appendix, table of contents, whatever). In general, if you click on the 'Back' button it will bring to to the point of departure in the document from which you came.Copyright (c)Roy Johnston, Ray Millard, 2005, for e-version; content is author's copyright,